


The Java Stream API, introduced with Java 8, enables easy processing of collections with the usage of lambda expressions that we have looked over in the previous article.
Collections is a widely used data structure API in Java, but the operations on the collections require specific code for each use case and do not allow making fluent queries on the data. Think that when you write a SQL query on a table how you feel comfortable and easy to write complex filters on data, and remember that the difficulty making such operations on Java collections.
At this point, Java Lambda Expressions and Stream API is now on the play as of Java 8. We have already covered the basics of Java Lambda Expressions, and; in this article, we will mostly focus on the Java Stream API with that easy processing of collections can be made using a declarative notation. Meaning that you do not need to write your data manipulation code as specific and to the point of a use case rather, you declare the operations to be executed on the data and that operations are executed when you run the terminal operation on the stream.
Stream API is located in the package java.util.stream.
Now, basics first.
1. Stream Terminology and Basics
So what’s a stream and why do we need such a new structure instead of operating directly on the collections?
1.1 Stream
A stream is a sequence of elements just like a collection. These sequences of elements are sourced from a data structure such as a collection or an array etc.
So as you see, both streams and collections represent a set of values. However, besides this, a stream supports declarative operations on the data.
Simply put:
Collections –> Data
Streams –> Data with processing operations
Okay, now we know that a stream is about a sequence of elements, plus operations on it, good.
1.2 Stream Iteration
Another aspect of a stream is that a stream can be traversed only once as in iterators. But here again, a stream differs from a collection in the way of that
- A stream has an internal iteration over the elements. Meaning that there is no explicit iterator; instead, the iteration is done internally without explicit coding.
- When iterating internally over the elements, for each element; several intermediate operations such as filtering and transformation can be executed with the usage of lambda expressions.
1.3 Stream Operations
Operations on a stream are either intermediate or terminal.
- Intermediate
An intermediate operation on a stream returns a new stream and so; this enables us to chain multiple intermediate operations in a single statement.
Intermediate operations are lazy which means the operation on the source is performed only when the terminal operation is executed and only on the elements that are necessary. - Terminal
A terminal operation is an actual operation that acts on the elements remaining after all the intermediate operations.
We will deeply cover these operations in this article.
1.4 Stream Pipeline
We have already noted that a stream is about data plus a processing operation on it. Then, what if we need a chain of operations?
Here is the answer; various methods can be chained on the elements of a stream in a single statement. That’s called method chaining and is just like a builder pattern style.
The chain of operations using streams is called a stream pipeline that consists of:
- a source that is a collection, file, or stream.
- zero or more intermediate operations such as filter, map, peek.
- one terminal operation such as forEach, count, collect..
2. Creating and Executing a Pipeline
A pipeline consists of a collection, several intermediate operations, and a terminal operation as mentioned above. The pipeline creation schema that’s describing this flow is given below.
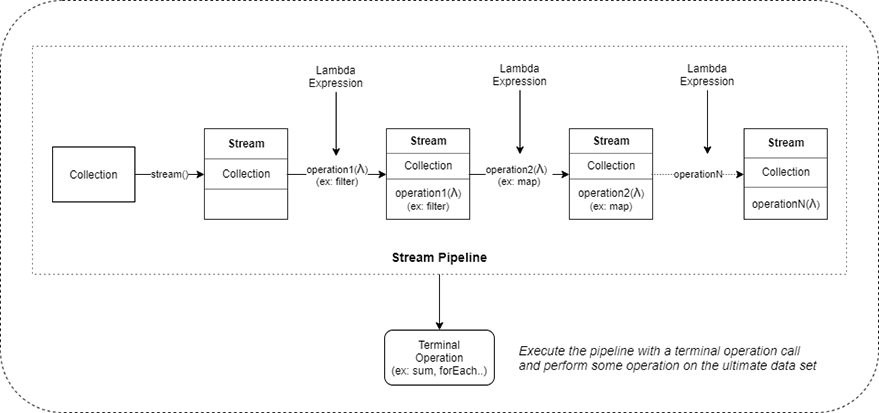
And a code sample is simply just like:
Double sum = salaries.parallelStream()
.filter(p -> p.getSalary() > 0)
.mapToDouble(p -> p.getSalary())
.sum();Let’s deep dive into the sample code above;
- A stream is created from a collection named salaries by calling the method parallelStream().
- The resulting stream here just references the collection with a special iterator called Spliterator.
- The methods stream() and parallelStream() are the two utilities added to Collection interface to create a stream from a collection instance.
- On a stream, we can call several intermediate operations, each of which creates a new stream, which helps us filtering or transforming the data on which we work. In the example above; at first, the filter intermediate operation is called.
- Calling an intermediate operation on a stream does nothing on the data, it’s just about the creation of a pipeline.
- By calling the method filter, a new Stream instance is created having the intermediate operation filter to be called later on subsequent to the terminal operation.
- After that, mapToDouble intermediate operation is called on the stream. This creates another stream having the mapToDouble operation to be called after the first intermediate operation which is the filter.
- Just note here that; parallel stream does not affect the calling sequence of the streams and so also the intermediate operations. Concurrency on a stream is about splitting the data into groups and processing each group concurrently in separate threads but in the order of intermediate operations just as specified in the pipeline creation.
- After calling the terminal operation which is sum here, each element in the stream is forwarded to the intermediate operations in the pipeline and ultimately the terminal operation is executed on the resulting data set.
In a nutshell, what explained so far is the outline of how the Stream API works. Now, it’s time to examine the processing operations provided by the API.
3. Intermediate Operations Provided by Stream API
The Stream API provides intermediate operations used to filter and transform the data on the backing collection and, the chain of these operations prepares the ultimate data on which the terminal operation runs.
Let’s see what these intermediate operations are and how they process the data.
3.1 filter
The filter operation, as its name suggests, filters the data by the Predicate provided. Meaning that it’s a declarative way of selecting the data with the conditional operations such as if or switch-case.
Stream<T> filter(Predicate<? super T> predicate);
This is the signature of the filter operation in the Stream interface. As you see, it returns a new Stream reference that could be used to chain the operations, just like in the builder-pattern style.
Let’s try it out in a sample code.
Arrays.asList("Abc", "Def", "Ghi", "Jkl")
.stream()
.filter(t -> !t.contains("A"))
.forEach(t -> System.out.println(t));In the code above,
- line2: a Stream of strings is generated –> Stream<String>
- an internal iterator runs on the Stream by calling the terminal operation on line4.
- line3: for each one of the strings a filter tests a Predicate on the current data and selects if it’s passed;
in our case, it simply selects the current string if it does not contain “A” - line4: and ultimately with a terminal operation forEach, the resulting data is printed out for each iteration.
That’s all about the filter operation. It is one of the widely used intermediate operations that you will often use it in your code.
3.2 map
The map operation makes a transformation on the data with a Function provided. Meaning that it’s a declarative way of converting the data in a Stream into another form and, this gives way to running with the new form of the data in the next processing operations.
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
This is the signature of the map operation in the Stream interface.
Let’s try it out in a sample code.
Arrays.asList("60", "70", "80", "90")
.stream()
.map(t -> Integer.valueOf(t))
.filter(t -> t > 70)
.forEach(t -> System.out.println(t));In the code above,
- line2: a Stream of strings is generated
- an internal iterator runs on the Stream by calling the terminal operation on line5.
- line3: for each one of the strings a transformation is done with the use of a Function provided in the map operation.
In our case, the function simply converts the String value into an Integer value.
Note that, here, the map operation itself does not run the transformation immediately; it only creates a Stream<Integer> to specify the resulting stream of the data after the transformation operation. - line4: a filter operation again tests a Predicate but this time on the transformed data.
That’s all about the map operation. It is one of the widely used intermediate operations used to transform the data.
3.3 flatMap
The flatMap operation can be used to make a flat stream from a multiple-level stream. Think that, you have a Stream<Stream<String>> and want to iterate over all the elements, then you have to flatten this multi-level stream into a flatten one such as Stream<Stream>. To do that, we use flatMap operation.
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
This is the signature of the flatMap operation in the Stream interface.
Let’s try it out in a sample code.
//Teams starting with a 'B'
List<List<String>> listOfGroups = Arrays.asList(
Arrays.asList("Galatasaray", "Bursa Spor"),
Arrays.asList("Barcelona", "Real Madrid", "Real Sociedad"),
Arrays.asList("Juventus", "Milan")
);
listOfGroups.stream()
.flatMap(group -> group.stream())
.filter(t -> t.startsWith("B"))
.forEach(t -> System.out.println(t));In the code above,
- line8: a Stream of List<String> is generated
- line9: to iterate over all the elements of all the lists, we flatten the stream by using the flatMap to Stream<String>.
Here in detail, we have a Stream<List<String>> but, we want to iterate over all Strings, not to iterate separately over Lists. So we call flatMap and, the Function passed to the flatMap makes a transformation converting the List<String> to a Stream<String> and merges that Streams into a new one and that provides a single-level flattened stream of String elements.
3.4 peek
The peek operation can be thought as an intermediate Consumer for all the elements of the stream. Meaning that, it does not change the elements of the stream but could be used to do some intermediate processing, such as logging, over them just before the next operations.
Stream<T> peek(Consumer<? super T> action);
This is the signature of the peeks operation in the Stream interface.
The peek operation is ideal for printing intermediate results or debugging operations. It’s strongly recommended that you should not change the elements on the data in the Consumer of the peek since this type of manipulation of the data is not thread-safe and discouraged.
Let’s try it out in a sample code.
List<String> names = new ArrayList<>(Arrays.asList("Erol", "Zeynep", "Yusuf", "Can"));
names.stream()
.filter(p -> p.length() > 3)
.peek(c -> System.out.println("Filtered Value: " + c))
.map(m -> m.toLowerCase())
.peek(c -> System.out.println("Lower Case Value: " + c))
.collect(Collectors.toList());3.5 distinct
The distinct operation can be used to eliminate the duplicated values in a stream. It does not have any parameter; here is the signature of it in the Stream interface:
Stream<T> distinct();
If the underlying collection of the stream is a Set, then you would not need this operation. But in case of other data structures, like Lists, that allow duplicated values, you may need to eliminate the duplicated values by calling distinct on the stream.
List<String> names = new ArrayList<>(Arrays.asList("Erol", "Zeynep", "Yusuf", "Can", "Erol"));
names.stream()
.filter(p -> p.length() > 3)
.distinct()
.map(m -> m.toLowerCase())
.forEach(t -> System.out.println(t));3.6 limit
The limit(long size) operation creates a new stream from the current stream, containing as many elements as the value given by the parameter size.
Stream<T> limit(long maxSize);
Let’s look over the following samples:
In the first sample, the first 2 items are taken from the filtered ones and collected to a list:
Stream<String> stream = Stream.of("abc", "defg", "hi", "jkl", "mnopr", "st");
List<String> list = stream
.filter(s -> s.length() < 4)
.limit(2)
.collect(Collectors.toList());
System.out.println(list); // prints --> [abc, hi]
And in the following sample, the first 2 items are taken from the stream and then they are filtered:
Stream<String> stream = Stream.of("abc", "defg", "hi", "jkl", "mnopr", "st");
List<String> list = stream
.limit(2)
.filter(s -> s.length() < 4)
.collect(Collectors.toList());
System.out.println(list); // prints --> [abc]3.7 skip
The skip(long n) operation creates a new stream consisting of the remaining elements of the current stream after discarding the first n elements.
Stream<T> skip(long n);
In the following sample, we skip the first n values of the filtered items from the list and collect the remaining items to a list:
Stream<String> stream = Stream.of("abc", "defg", "hi", "jkl", "mnopr", "st");
List<String> list = stream
.filter(s -> s.length() < 4)
.skip(2)
.collect(Collectors.toList());
System.out.println(list); //prints --> [jkl, st]3.8 sorted
The sorted operation creates a new stream consisting of the elements of the current stream, sorted according to the provided Comparator if and only if the underlying collection is ordered such as List, TreeSet.
Stream<T> sorted(Comparator<? super T> comparator);
Let’s look over the following samples:
List<String> list = Arrays.asList(new String[]{"1", "7", "0", "4", "4"});
List<String> sortedList = list.stream()
.sorted(Comparator.comparing(t -> Integer.parseInt(t)))
.collect(Collectors.toList());And for the reverse ordering:
List<Integer> numbers = new ArrayList<>(Arrays.asList(4, 2, 5, 8, 12, 3, 6, 9, 7));
numbers.stream()
.sorted((a, b) -> Integer.compare(a, b))
.sorted(Comparator.reverseOrder())
.forEach(p -> System.out.println(p));4. Terminal Operations Provided by Stream API
The Stream API provides several terminal operations executed as a last step after the declaration of the intermediate operations. The terminal operations actually starts the internal iteration and the execution of the stream pipeline declared via the chained operations.
Let’s see what these terminal operations are and how they run in the process.
4.1 forEach
The forEach terminal operation performs an action for each element of the stream. It consumes the data on the stream, so gets a Consumer and returns nothing.
void forEach(Consumer<? super T> action); void forEachOrdered(Consumer<? super T> action);
We have already looked over it in the previous samples. Here, it will be good to remark the difference of forEachOrdered from forEach.
Stream.of("a1","b2","c3").parallel().forEach(t -> System.out.println(t));
Stream.of("a1","b2","c3").parallel().forEachOrdered(t -> System.out.println(t));As you can try out in the sample code above; forEachOrdered guarantees the preserving the encounter order of the stream. So the second line always prints a1, b2, c3 in order. However, in the first line, this order is not guaranteed.
4.2 collect
The collect terminal operation performs a mutable reduction operation on the elements of the stream by creating a collection. Meaning that, it basically collects the resulting items in the stream into a specified collection.
<R, A> R collect(Collector<? super T, A, R> collector);
The collect operations take an argument Collector to collect the items into a collection. We mostly leverage the utility methods giving the often-used Collector implementations in the Collectors helper class.
Set<String> names =
Stream.of("Erol", "Zeynep", "Yusuf", "Erol")
.collect(Collectors.toSet());
System.out.println(names);4.3 count
The count terminal operation returns the count of elements in the stream.
List<String> list = Arrays.asList(new String[]{"1", "2", "3", "4", "4"});
long count = list.stream()
.filter(t -> !t.equals("1"))
.count();
System.out.println("count: " + count);4.4 min/max
The min/max terminal operations return the minimum/maximum element of the stream according to the provided Comparator.
Optional<T> min(Comparator<? super T> comparator); Optional<T> max(Comparator<? super T> comparator);
Let’s try out the following samples:
List<String> list = Arrays.asList(new String[]{"1", "2", "3", "4", "4"});
String max = list.stream()
.filter(t -> !t.equals("1"))
.max(Comparator.comparing(t -> Integer.parseInt(t))).get();
System.out.println("max: " + max);List<String> list = Arrays.asList(new String[]{"1", "2", "3", "4", "4"});
int max = list.stream()
.filter(t -> !t.equals("1"))
.mapToInt(t -> Integer.valueOf(t))
.max()
.getAsInt();
System.out.println("max: " + max);4.5 sum
The sum terminal operation returns the sum of elements in an IntStream.
Let’s try out the following sample:
List<String> list = Arrays.asList(new String[]{"1", "2", "3", "4", "4"});
double sum = list.stream()
.mapToDouble(t -> Double.parseDouble(t))
.sum();
System.out.println("sum: " + sum);4.6 average
The average terminal operation returns the arithmetic mean of the elements of an IntStream.
Let’s try out the following sample:
List<String> list = Arrays.asList(new String[]{"1", "2", "3", "4", "4"});
double average = list.stream()
.mapToDouble(t -> Double.parseDouble(t))
.average()
.getAsDouble();
System.out.println("average: " + average);4.7 reduce
The reduced terminal operation performs a reduction in the elements of the stream.
int reduce(int identity, IntBinaryOperator operator);
Meaning that, for each element in the stream, the binary operator is performed using the result of the previous operation as the first input of the next iteration.
Let’s try out the following sample to understand it well:
int result = IntStream.rangeClosed(1, 5).parallel()
.reduce(0, (sum, element) -> sum + element);
System.out.println("sum of [1, 5]: " + result);Note that, here the integer value of 0 is passed into the reduced method. This is called the identity value and represents the initial value for the reduce function and the default return value in case of no members in the reduction.
5. Some More Advanced Scenarios
5.1 Group By
We can group the elements of a stream by a specific key value. The groupingBy method in the Collectors helper class returns a Collector for the map implementation to be able to realize this case.
Let’s look over the following samples:
List<String> list = Arrays.asList(new String[]{"1", "7", "0", "4", "4"});
//group by hashCode to value
Map<Integer, List<String>> map = list.stream()
.collect(Collectors.groupingBy(t -> t.hashCode()));
map.forEach((k,v) -> System.out.println(k + ": " + v));List<String> list = Arrays.asList(new String[]{"1", "7", "0", "4", "4"});
//group by hashCode to length
Map<Integer, Long> summingMap = list.stream()
.collect(Collectors.groupingBy(t -> t.hashCode(), Collectors.summingLong(t -> t.length())));
summingMap.forEach((k,v) -> System.out.println(k + ": " + v));5.2 collect, groupingBy, averagingLong, summingInt, maxBy, comparingLong, joining
Map<Integer, List<String>> defaultGrouping = names.stream().collect(groupingBy(t -> t.length()));
Map<Integer, Set<String>> mappingSet = names.stream().collect(groupingBy(t -> t.length(), toSet()));
mappingSet = names.stream().collect(groupingBy(t -> t.length(), mapping(t -> t, toSet())));
//grouping by multiple fields
Map<Integer, Map<Integer, Set<String>>> multipleFieldsMap = names.stream().collect(groupingBy(t -> t.length(), groupingBy(t -> t.hashCode(), toSet())));
//average w.r.t lengths
Map<Integer, Double> averagesOfHashes = names.stream().collect(groupingBy(t -> t.length(), averagingLong(t -> t.hashCode())));
//sum w.r.t lengths
Map<Integer, Long> sumOfHashes = names.stream().collect(groupingBy(t -> t.length(), summingLong(t -> t.hashCode())));
//max or min hashCode from group
Map<Integer, Optional<String>> maxNames = names.stream().collect(groupingBy(t -> t.length(), maxBy(comparingLong(t -> t.hashCode()))));
Map<Integer, String> joinedMap = names.stream().collect(groupingBy(t -> t.length(), mapping(t -> t, joining(", ", "Joins To Lengths[", "]"))));
joinedMap.forEach((k,v) -> System.out.println(k + ": " + v));5.3 Split a colletion into smaller chunks
List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
int chunkSize = 3;
AtomicInteger counter = new AtomicInteger();
Collection<List<Integer>> result = numbers.stream()
.collect(Collectors.groupingBy(it -> counter.getAndIncrement() / chunkSize))
.values();
result.forEach(t -> System.out.println(t));5.4 Concatenation
List<String> list = Arrays.asList(new String[]{"1", "7", "0", "4", "4"});
String str = list.stream()
.collect(Collectors.joining(", "));
System.out.println("concatenated: " + str);5.5 Collections max/min
Deque<String> stack = new ArrayDeque<>();
stack.push("1");
stack.push("2");
stack.push("3");
System.out.println("max in the stack: " +
Collections.max(stack, (s, t) -> Integer.compare(Integer.valueOf(s), Integer.valueOf(t))));
System.out.println("min with max method via using different Comparator: " +
Collections.max(stack, (s, t) -> Integer.compare(1/Integer.valueOf(s), 1/Integer.valueOf(t))));6. Stream API Enhancements in Java 9
6.8.1 Stream.iterate
Stream.iterate in Java 8 creates an infinite stream.
Stream.iterate(initial value, next value)
Stream.iterate(0, n -> n + 1)
.limit(10)
.forEach(x -> System.out.println(x));JDK 9 overloads iterate with three parameters that replicate the standard for loop syntax as a stream.
For example, Stream.iterate(0, i -> i < 5, i -> i + 1) gives you a stream of integers from 0 to 4.
Stream.iterate(initial value, stopper predicate, next value)
Stream.iterate(1, n -> n < 20 , n -> n * 2)
.forEach(x -> System.out.println(x))
;6.8.2 takeWhile
With the method takeWhile, we can now specify the condition of the iteration as of the third parameter in the new overriden version of the iterate method in Java 9.
Stream.iterate("", s -> s + "t")
.takeWhile(s -> s.length() < 10)
.reduce((first, second) -> second) //find last
.ifPresent(s -> System.out.println(s));
;6.8.3 dropWhile
dropWhile removes the elements while the given predicate returns true.
System.out.print("when ordered:");
Stream.of(1,2,3,4,5,6,7,8,9,10)
.dropWhile(x -> x < 4)
.forEach(a -> System.out.print(" " + a));
System.out.print("when unordered:");
Stream.of(1,2,4,5,3,7,8,9,10)
.dropWhile(x -> x < 4)
.forEach(a -> System.out.print(" " + a));6.8.4 Extracting null values – ofNullable
Extracting null values in Java 8:
Stream.of("1", "2", null, "4")
.flatMap(s -> s != null ? Stream.of(s) : Stream.empty())
.forEach(s -> System.out.print(s));Extracting null values in Java 9 – ofNullable:
Stream.of("1", "2", null, "4")
.flatMap(s -> Stream.ofNullable(s))
.forEach(s -> System.out.print(s));7. Code Samples
In this article, we have looked over the Java Stream API and tried out samples on typical use cases by leveraging the lambda expressions that we have covered in the previous article.
You can see the sample code for this article on my Github page:
https://github.com/erolhira/java