

As established in our previous articles, Python is one of the most popular programming languages for a reason: its clear syntax and incredible power allow developers to utilize it in various areas — scripting/automation, web development, science, and so on. One of the areas where Python quickly rose to prominence is data science — you’ve probably noticed it by the abundance of “Become a data scientist with Python!” courses. Our experience tells us that you should also articles that focus on single aspects of Python as a programming language:
- Python map() Explained and Visualized
- Python enumerate() Explained and Visualized
- Python range() Explained and Visualized
- Responsible Web Scraping: Gathering Data Ethically and Legally
- “Learn Python the Hard Way”: a Detailed Book Review
- A Roundup Review of the Best Deep Learning Books
- Flask vs. Django: Let’s Choose the Right Framework for the Job
There is a subfield of data science that is particularly interesting: it’s called Natural Language Processing (or NLP for short, although Google may confuse this abbreviation with “Neuro-linguistic programming”). NLP developers are solving important and challenging tasks, utilizing a plethora of Python-based tools. In this article, we’ll explore various Python libraries designed for natural language processing and analyze the importance of this particular subfield.
Importance of Natural Language Processing
Before we begin, we need to answer a question that may appear trivial on the surface: “Why do we need to process natural languages at all?” To understand the importance of language processing, we should keep in mind that the so-called “big data” — massive heaps of information collected by modern web apps and services” — is primarily comprised of various instances of communication between people. Although numbers and everything they create are important, communication relies heavily on the language, and so automating the process of processing and understanding languages is critically important.
To understand this topic better, we need to make a clear distinction between natural and artificial languages:
- Natural languages (e.g. English, Spanish, or Chinese) have been evolving over the course of human history, for thousands of years. Although each natural language does have a
- Artificial languages, on the other hand, are created as a superset of human communication; they are usually domain-specific and very formal, which allows them to maximize their efficiency. The most obvious example is programming languages. Can you come up with more examples? 🤔

Natural language processing, therefore, aims to design systems capable of understanding human languages. Despite the advancements in the last decade, actually understanding a language is such a complicated task that only Artificial general intelligence (i.e. artificial intelligence that learns outside predefined algorithms, akin to the human mind) can attempt to solve it.
Here’s a quick shower thought: when A.I. finally tackles processing natural languages, it may also master artificial languages as an added bonus. Having understood, say, the word “print” (its various meanings and contexts in which it can be used), it can also grasp how to use the print function.
Why Is Natural Language Processing (Primarily) Done with Python?

A good reason for Python’s dominance in the data-oriented areas (i.e. data science, machine learning, and natural language processing) is Python’s simplicity. Data science (and, by extension, NLP) is a field comprised primarily of scientists/analysts, while programmers are represented more in areas like software/web development or systems/network engineering.
This means that many people in the data science industry haven’t been necessarily exposed to certain quirks of programming logic. A good example is how the starting index in more general programming languages is 0, but in math-specific languages like FORTRAN, MATLAB, Lua, and Erlang, the starting index is 1.
In this regard, Python offers similar benefits. One of Python’s advantages over its competitors like C(++) and Java lies in its simplicity — we can take various implementations of the Hello World as a (somewhat humorous) example:
// Java implementation
class HelloWorld
{
public static void main(String args[])
{
System.out.println("Hello World");
}
}
// C++ implementation
#include<iostream>
using namespace std;
int main()
{
// prints hello world
cout<<"Hello World";
return 0;
}
# Python implementation print(“Hello World”)
Although the number of characters isn’t the most important factor, Python’s simplicity helps immensely to make the code more readable, facilitating easier collaboration between team members who don’t have a decade of programming experience.
NLTK

Natural Language Toolkit has been the go-to tool for many people starting their NLP journey; it balances great functionality with a not-too-steep learning curve pretty well. Released almost 20 years ago, back in 2001, it was an impressive piece of software. Nowadays, however, its competitors have caught up and are introducing new features much quicker.
NLTK is far from the best’ tool available to us. Its release date gives a hint why: the latest advancements in machine learning (deep learning in particular) have paved the way for more modern frameworks which adopted a different approach: “Be faster and focus on less features.”
NLTK is often referred to as “swiss army knife” and we think that this comparison is spot-on: although it does offer a plethora of tools, it doesn’t really dominate any of its domains — it’s unable to keep up with modern NLP tools.
Its users also complain about this software’s bugginess and overall subpar performance. Upon taking a look at NLTK modules, it’s easy to see why: NLTK is an 18-year-old software in an incredibly fast changing market.

However, NLTK makes up for its functionality with its learning resources. Some of them include:
- The NLTK book serves as a great guide to the tool itself — but it also manages to introduce the reader to both Python and natural language processing. The reader, therefore, can delve into NLTK without any prior Python knowledge (but we don’t think this is would be a sufficient introduction to Python — the NLTK book focuses more on practice instead of theory).
- The HOWTO section showcases many of NLTK’s features separately.
- The Modules section explains how various NLTK modules operate under the hood and how they should be used.
Still, we shouldn’t regard NLTK as “completely obsolete” — thanks to contributions from numerous open-source supporters, the NLTK project stays functional and can offer you some great features. A few of them include:
- Tokenizer.
- Stemmer.
- Visualization tools.
- Wrappers for other NLP libraries.
Installing NLTK and Playing Around
To install NLTK, you would need:
- Python 2.7/Python 3.5, 3.6, or 3.7.
- virtualenv.
- Numpy.
The installation process is trivial — you follow the guide and confirm that NLTK works correctly via running import nltk in the Python interpreter. Upon installing NLTK data (the last section in the guide we linked above), you can finally try some of NLTK’s functionality out. The project’s dataset contains various books whose content you can play around with: “Moby Dick”, “Sense and Sensibility”, “The Book of Genesis”, “Monty Python and the Holy Grail” (after all, Python’s name was inspired by the British comedy group), and others.
Let’s input the following command and see the results for ourselves:
text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])
This command will open a new window with this interface:
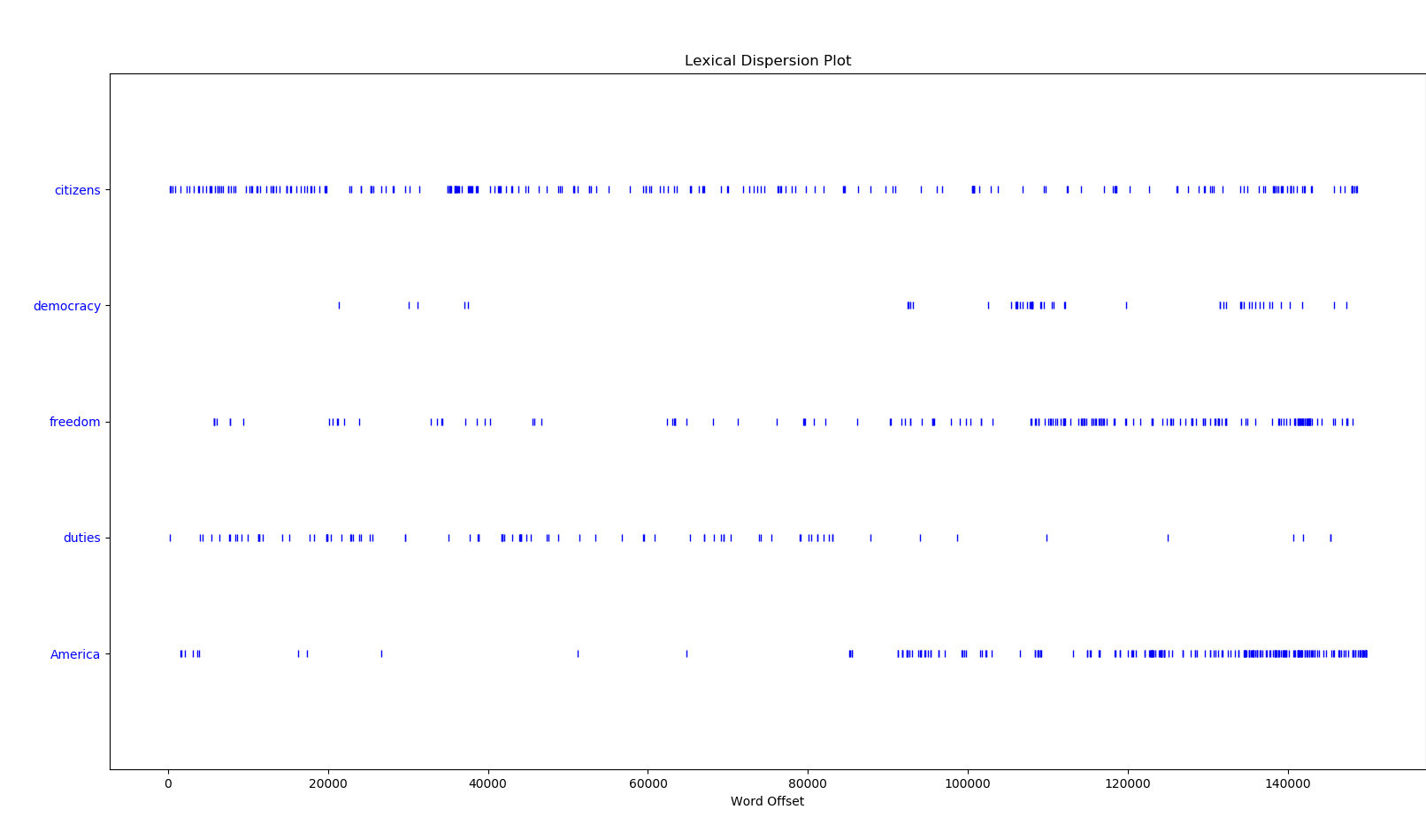
text4 is the Inaugural Address Corpus from the NLTK dataset; we call the dispersion_plot() function to visualize how often these words occur and where they can be found. This is one of NLTK’s simplest functions — imagine what projects you can build once you become more experienced with it!
spaCy

spaCy is a free open-source library. Released in 2015 (v1), it got even more upgrades in 2019 (v2), implementing new deep learning models. This is an important detail that sets spaCy from tools like NLTK apart: it gets frequent updates and generally tries to keep with the latest NLP innovations. Some of its main features include:
- Deep learning integration.
- Support for 52+ languages.
- Non-destructive tokenization.
- Named entity recognition.
- Various statistical models.
The set of features above stands testament to how dedicated spaCy developers are to maintaining their project. We can only imagine what version 3 will bring us…
spaCy boasts many exciting features, but we should definitely begin with its backstory. Like many great technologies, it started out of necessity — a necessity for a better natural language processing solution. spaCy’s creator, Matthew Honnibal, explains his frustration with NLTK in his blog post titled Dead Code Should Be Buried:
Various people have asked me why I decided to make a new Python NLP library, spaCy, instead of supporting the NLTK project. This is the main reason. You can’t contribute to a project if you believe that the first thing that they should do is throw almost all of it away. You should just make your own project, which is what I did.
The criticism outlined by Matthew Honnibal is justified: the market of NLP tools is changing every year at an incredible speed, so it doesn’t make sense to indulge old software which isn’t capable of keeping up anymore.
spaCy’s creators describe this tool as an “industrial-strength natural language processing tool”. As spaCy came about in the deep learning era, it is specifically designed to integrate with deep learning models that have made natural language processing so exciting in the last few years.
Natural Language Processing Use Case — StockerBot

NLP may seem like a niche set of technologies, but it actually drives a lot of innovations. It is often applied to make informed financial decisions — it’s impossible for a single person to keep up with a myriad of news, statements, updates, updates, and reports associated with hundreds and hundreds of companies. In part, this task can be automated — an NLP-driven program can be trained to recognize “good news” and “bad news” and, say, buy or sell the given company’s stocks. While this program would have the upper hand in reaction time and scalability (i.e. the ability to monitor all streams of financial data concurrently), it falls flat in long-term planning — A.I. cannot integrate contextual knowledge… yet. 🤖
StockerBot follows a similar logic. It was designed to:
- Develop a dataset featuring “financial language” (i.e. sentences with financial sentiments) →
- Tag each sentence →
- Build a sentiment analysis model fine-tuned for investing jargon.
A crucial component of this particular project (and natural language processing in general) is sentiment analysis, i.e. automated computational assessment of various emotions and opinions found in the text to determine the author’s attitude (positive/negative/neutral) towards a particular topic or product. This may sound like a complicated explanation, so let’s head over to the online interface and interact with it.
However, when encountering sentences with not-so-obvious meanings (idioms in particular), these programs often fail to classify the sentiments correctly. Let’s input these two phrases:
- “I’ve seen better.” (Although this phrase is nuanced, we can agree that it generally means “It’s bad.”, giving it a negative tone)
- “I’ve seen worse.” (This phrase, on the other hand, generally means “It’s OK.”, giving it either a positive or a neutral tone)
NLTK’s text classification tool views phrase #1 as “positive” and phrase #2 as “negative”. Here lies the problem with text classification and sentiment analysis: while individual tokens can be mapped to their corresponding meanings, the context can alter the meaning substantially.
StockerBot’s creator, David Wallach, reiterates this problem in the project’s Readme:
One main objective of this project is to classify the sentiment of companies based on verified user’s tweets as well as articles published by reputable sources. Using current (free) text based sentiment analysis packages such as nltk, textblob, and others, I was unable to achieve decent sentiment analysis with regards to investing. For example, a tweet would say Amazon is a buy, you must invest now and these libraries would classify it as negative or neutral sentiment. This is due to the training sets these classifiers were built on. For this reason, I decided to write a script (scripts/classify.py) that takes in the json representation of the database downloaded from the Firebase console (using export to JSON option) and lets you manually classify each sentence.
StockerBot isn’t an exactly world-renowned project — it only has 11 GitHub stars and a small handful of users. Its limited popularity, however, helps to drive one important point home: as a technology, natural language processing isn’t exclusive to large tech companies; it doesn’t require immense computational power that only Google can afford — on the contrary, every developer can create a small-scale project with awesome functionality.
Natural Language Processing Job Market
This section deserves a fair warning to everyone planning to choose general data science/natural language processing as their career: the glamorous image of the data scientist created by various media and platforms isn’t really true — at least not anymore.
This disenchantment is perfectly summarized by a data science/machine learning consultant Vicki Boykis in a blog post titled Data science is different now — you can read the post itself to get a much better explanation of how the data science field has changed over the years. In essence, the media have been hyping data science up as the sexiest job of the 21st century
, also focusing on high salaries. You might’ve noticed an increasing number of “Become a data scientist fast!” courses and bootcamps — this is a direct result of this trend.
As a person with substantial experience in this field, Vicki Boykis points a glaring problem that besets the entire data science industry: supply and demand don’t match as the market is starting to become oversaturated with data science specialists.
Another problem has to do with job perception/expectations: novice data scientists are expecting that their workflow is going to be a stream of challenging and futuristic tasks: training A.I. models and writing their own algorithms. The reality, however, is different: the bulk of data science work is not science, but data:
- Mastering SQL (i.e. reading our SQL interview questions),
- Understanding how databases work,
- Becoming proficient with JSON,
- Working with Jupyter notebooks,
- Version controlling data and SQL,
- Creating Python packages,
- Putting R in production,
- And more “unglamorous” stuff.
In essence, the prosaic aspects of data science (i.e. cleaning, moving, analyzing, and presenting data) are far more common than their exciting counterparts (the creative process behind picking and deploying a machine learning model in production, for instance).
Although Vicki doesn’t talk about the natural language processing market in particular, she did confirm that the same oversaturation trend applies to it as well.
An essential prerequisite for natural language processing — and data science in general — is a solid grasp of mathematics, namely:
- Calculus.
- Linear algebra.
- Probability theory.
- Statistics.
At this point in the article, you’re probably typing “math courses” on Udemy or Coursera. While these do offer some great material, you can also use free courses available on the MIT OpenCourseWare — it hosts the entirety of MIT course content. Here you can find all math-related material.
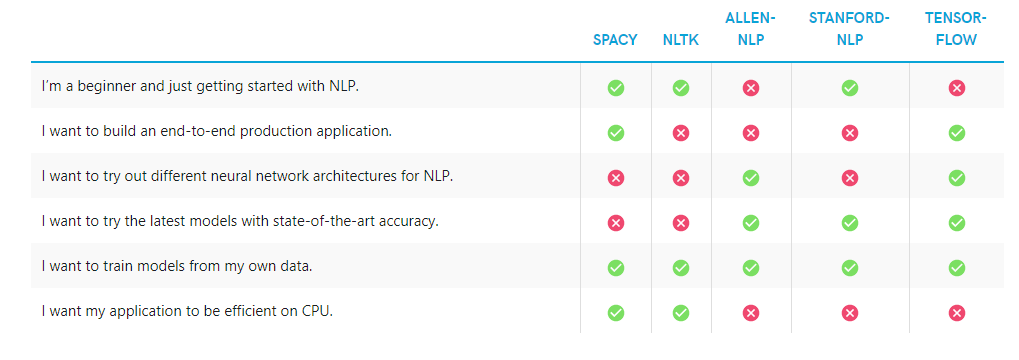
Which NLP Tools Should I Use for What Project?
spaCy provides a great overview of the libraries we’ve discussed in this article. Let’s summarize their findings in the table below:
Conclusion
The field of natural language processing is changing rapidly — in just a few years, this very article may be rendered obsolete as new breakthrough frameworks and libraries enter the market. Still, we’ll do our best to keep you updated on the latest programming technologies that catch our attention! 🙂