Data Science Overview: The Bigger Picture

 For the last ~5 years, “data science” has been a hot term that continuously gathered traction both in the IT world and the media. With buzzwords like “big data” and “machine learning”, data science rose to prominence as the technology that could solve every problem imaginable… well, at least it’s hailed as one. This praise, although not completely unwarranted, seems too good to be true — so how does data science function in the real world?
For the last ~5 years, “data science” has been a hot term that continuously gathered traction both in the IT world and the media. With buzzwords like “big data” and “machine learning”, data science rose to prominence as the technology that could solve every problem imaginable… well, at least it’s hailed as one. This praise, although not completely unwarranted, seems too good to be true — so how does data science function in the real world?
Much like cryptocurrencies, it’s an incredibly broad technology with lots of implications, limitations, and intricacies — so summarizing this topic in a few sentences is impossible. Instead, we continue our “Fundamentals” series (its previous installment covers hiring a freelance web developer) and dedicate a whole article to exploring data science more thoroughly: what is data science? How can it be used? What technologies are involved? Which problems and caveats should be avoided? Let’s find out.
Getting the definition right

Too bad not all dictionaries have caught up
First of all, we should stress that data science is a multidisciplinary field that incorporates a number of technologies, professions, and approaches. Journal of Data Science, a publication that has been at the forefront of this field, defines data science as almost everything that has something to do with data: Collecting, analyzing, modeling… yet the most important part is its applications — all sorts of applications.
In a sense, it can be compared to the term “medicine”, so a phrase like “I’m a data scientist” is as ambiguous as “I’m a doctor” — it does point in the general direction of what this person does, but doesn’t really explain anything beyond that. A good method of understanding a profession can be summarized in the following question: “What problems do the people of this profession solve?” Well, data scientists use data to create an impact for a given business, research, etc.
The rise of data-driven approach is heavily linked to the emergence of Web 2.0: in essence, this new rendition of the internet emphasized interactivity and user-generated content, allowing users to leave so-called “digital footprints” — videos they liked, pictures they shared, search queries they sent, and much more. This information came to be known as “big data”.
Individually, these data points aren’t insightful at all (“John Doe from Michigan City, Indiana, liked a video about the Linux file system” — so what?), but collectively, they reveal hidden correlations, trends, and — in essence, data science provides bird’s-eye view over the problem.
Creating impact
In other words, are we even going in the right direction?
The very essence of any data science job is solving problems: the company provides you with (often ambiguous) data sets and expects you to make something out of it — something that can help solve a real business problem. When analyzed correctly, data can provide a lot of valuable insights into how the business operates at the moment — and which aspects could be improved upon. Some of them are:
- Identifying key business metrics that should be tracked
- Predicting the performance of these metrics
- Predicting the behavior of customers
- Testing product changes via experiments
- Improving the product via the creation of data products
Success metrics and tracking metrics
Proficiency in data science/analysis doesn’t end with formal technical competencies, though: success and tracking metrics also need to be analyzed. The problem with this skill set lies in its complexity: understanding the key metrics of the product/service is something that product managers typically do — this means that the data scientist should also understand the product they’re working on well.
For a typical social media platform, success metrics would include:
- Active users
- Quality standards
- User satisfaction
Tracking metrics, on the other hand, are:
- Time spent (per user)
- Content consumed (e.g. how many videos/pictures watched)
- Content interacted with (e.g. likes, comments, shares)
- Content created (e.g. how many videos/pictures uploaded)
- Forced quits (because every instance of negative user experience is equally important)
Technologies and skills

Pride of any data scientist
Still, data science is heavily tied to all technological tools that enhance it: programming languages create the infrastructure, then tests are conducted, and then these findings need to be visualized and communicated.
Python & R
These programming languages are the best picks for any data science. It’s important to understand that they’re not competing for the “Best Language” title (in terms of raw numbers, Python is far more popular and developed); rather, these are two distinct tools and proficient data scientists can use both of them to their fullest potential.
Python excels at data processing thanks to its object-oriented and general-purpose nature: Python’s community has created a lot of packages (e.g. pandas, numpy, scikit-learn) optimal for data science and especially for machine learning.
R, although not as flexible as its counterpart, focuses on data analysis and really excels in this field — its packages allow for easy statistical computing, visualization (ggplot2), and standalone analysis.
Testing
Creating an impact is important, but it also needs to be tested sufficiently: just how well is this new feature doing? Has it improved our success metrics in any way? Does it have the potential to do it? When conducting tests, data scientists also need to gauge how many people they need in these testing groups, constantly balancing between “not enough participants for adequate analysis” and “so many participants that it’s starting to drain the budget”.
Therefore, data scientist utilize various testing techniques to ensure that the product is headed in the right direction. With A/B testing (also called split testing), data scientists divide their users into two groups and expose Feature A to Audience A and Feature B to Audience B. To do this test correctly, the difference between the two audiences must be marginal, while the difference between the two features must boil down to a single variable (e.g. putting the “Sign up now!” button either at the top or at the bottom)
SQL
In most cases, companies build their infrastructure in a SQL-driven manner to query all data. SQL, or Structured Query Language, is an indispensable tool for organizing data: while remote web developers work their front-end magic via the likes of Angular, React, and Vue.js, SQL manages the dirty work — ensuring that all the precious data is structured accordingly.
Therefore, SQL proficiency is crucial for any data science-related activity: retrieving and working with data is often done purely via SQL. Most importantly, SQL knowledge allows data scientists to interpret the structure, meaning, and relationships in source data, which then can be shaped for later use in analytical purposes. By the way, we’ve got some great SQL interview questions!
Caveats and misconceptions

Data science as a field received a lot of media attention (including privacy-related scandals like Cambridge Analytica) and there haven’t been just enough specialists to clarify misconceptions that arose during these events. Let’s clear some of these up:
Companies that don’t have a clear data science strategy
For some companies, “data science” is merely a hip trend to follow — but nothing more. This leads to situations where only one data scientist is hired; this poor data scientist is then expected to do all data-related assignments, effectively doing the work of different specialists.
To quote data science evangelist Jonny Brooks-Bartlett: Following on from doing anything to please the right people, those very same people with all of the clout often don’t understand what is meant by “data scientist”. This means that you’ll be the analytics expert as well as the go-to reporting guy and let’s not forget that you’ll be the database expert too.
This can be acceptable in a startup environment where the responsibilities of team members aren’t stable yet; in larger/older companies, however, this move might not work at all. As Ben Weber, Medium author who regularly busts data science-related myths, puts it: the company needs a clear understanding of how data science can improve its product. This means that simply hiring a data scientist is not enough; instead, company managers need to establish a data-oriented pipeline and avoid the “one person, three jobs” mentality.
“Data science = programming” or “Data science is purely technical”
Although programming skills are absolutely vital for this field, a proficient software engineer does not equal proficient data scientist: for the latter group, mathematics and statistics are arguably more important; while for some data analysts, programming per se isn’t even part of their job: they query all data via SQL and operate with/visualize it via Excel.
There is a skill that gets cited often: communication. In a technical profession, this competence seems wildly alien and out of place. However, finding data is not enough — data scientist also needs to communicate their findings, i.e. explain what they mean and what decision the management team should meet to create a positive impact.
Another important skill is visualization: it accompanies communication, helping the management team understand data easier. These two skills allow the data scientist to become a real storyteller, transforming rather abstract data into insightful and captivating stories. Public speaking and formal writing are valuable additions as well as there’s usually a lot of back-and-forth communication with product managers and engineers.
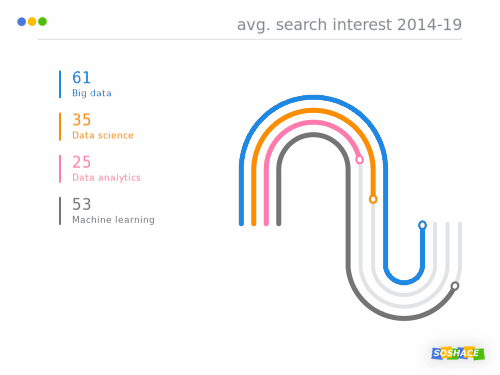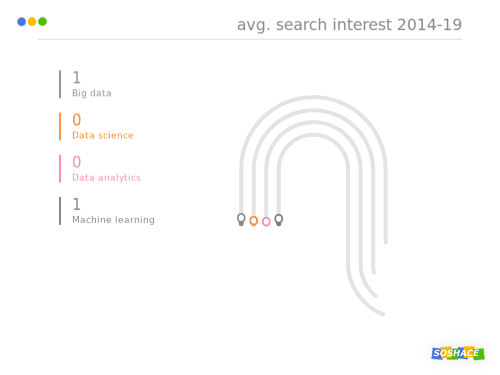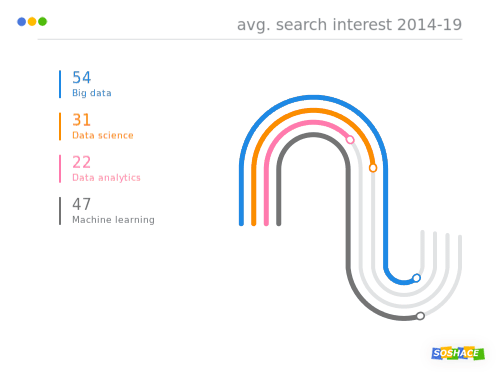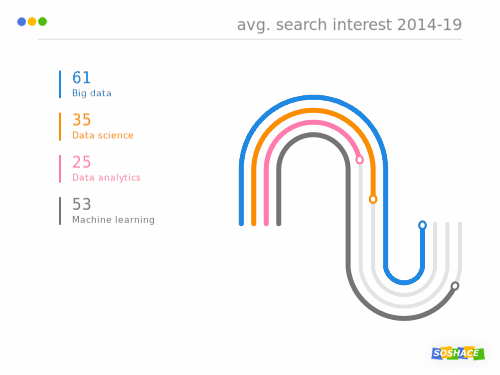
Data visualization rocks! (This is how data science search trends compare)
Conclusion
Data science is a large field with a lot of fascinating topics to cover — after all, there are entire blogs and journals dedicated to this area. Hopefully, we’ve also elaborated on these questions in a sufficient manner. 🙂 Although it features the word “science”, data science isn’t completely technical or math-focused — there’s a lot of room for creativity and novelty.
About the author



Top developers
-

 Tedi C. Full-stack React/PHP developerJSReactCSSPHPNode.jsShow lessAll skills
Tedi C. Full-stack React/PHP developerJSReactCSSPHPNode.jsShow lessAll skills Miodrag M. Senior React developerJSReactCSSShow lessAll skills
Miodrag M. Senior React developerJSReactCSSShow lessAll skills Alexey D. Frontend Developer
Alexey D. Frontend DeveloperRelated articles

 15.03.2024
15.03.2024JAMstack Architecture with Next.js
The Jamstack architecture, a term coined by Mathias Biilmann, the co-founder of Netlify, encompasses a set of structural practices that rely on ...
 19.01.2024
19.01.2024Training DALL·E on Custom Datasets: A Practical Guide
The adaptability of DALL·E across diverse datasets is it’s key strength and that’s where DALL·E’s neural network design stands out for its ...

 12.06.2023
12.06.2023The Ultimate Guide to Pip
Developers may quickly and easily install Python packages from the Python Package Index (PyPI) and other package indexes by using Pip. Pip ...
Categories



No comments yet