

Picture your Node.js app starts to slow down as it gets bombarded with user requests. It’s like a traffic jam for your app, and no developer likes dealing with that. This issue pops up because Node.js typically runs on a single thread, which can get overwhelmed easily. To tackle this, Node.js comes with a special tool called the cluster module. This tool lets your app split its workload across multiple worker processes. These processes can run at the same time and even share the same server port. By doing this, your app can make the most out of multi-core systems, boosting its ability to handle more users and tasks without slowing down.
In this article, we’re going to dive into how clustering works in Node.js. We’ll see how it turns a single-threaded app into a powerhouse that can deal with a lot more work. We’ll go over what the cluster module is, why it’s useful, and how you can use it in your Node.js apps. This is key info for backend developers, DevOps engineers, and solution architects looking to make their Node.js apps faster and more reliable.
Understanding Node.js and Its Single-Threaded Nature
Node.js is renowned for its speed and efficiency, largely due to its non-blocking, event-driven architecture. At its core, Node.js runs on the V8 JavaScript engine, which executes JavaScript code outside a web browser. One of the key characteristics of Node.js is its single-threaded nature. This means that by default, a Node.js application runs on a single thread of execution. While this simplifies programming models and works well for I/O-bound tasks, it also means that CPU-bound tasks can block the thread, leading to performance bottlenecks when handling a large number of requests.
The Challenge of Single-Threaded Applications
In a single-threaded environment, tasks are processed one at a time, in sequence. This can lead to inefficiencies, especially on modern hardware with multiple CPU cores. If a Node.js application receives hundreds or thousands of requests simultaneously, processing them sequentially can result in slow response times and a poor user experience.
Enter Clustering
Clustering is a technique that allows a Node.js application to take advantage of multi-core systems by launching multiple instances of the application, each running on its own thread. This effectively multiplies the application’s capacity to handle concurrent requests, turning a potential bottleneck into a smooth, scalable operation.

In this diagram, the single-threaded architecture shows all requests being handled by one main thread on a single CPU core, while the clustered architecture shows a master process creating multiple worker processes, each handling different requests on separate CPU cores.
The Node.js cluster Module
The cluster module in Node.js is what makes clustering possible. It provides a way to create child processes (workers) that run simultaneously and can share server ports. The module allows for easy communication between the master process and workers, facilitating a balanced distribution of tasks.
Key Features include:
- Easy creation and management of worker processes
- Load balancing across workers
- Shared server ports among workers
Core Concepts of Clustering
In this section, we’ll explore the fundamental principles behind clustering in Node.js, focusing on the master-worker architecture and the mechanics of the cluster module. We’ll also discuss the operating system’s role in managing these processes.
Master-Worker Architecture
The master-worker architecture is a system design pattern where a master process is responsible for managing one or more worker processes. In the context of Node.js:
Master Process: The master process is the initial process started by your Node.js application. Its primary role is to manage the creation and supervision of worker processes. It does not handle actual client requests but delegates this responsibility to the workers.
Worker Processes: Worker processes are the child processes spawned by the master process. Each worker runs its own instance of the Node.js application and handles client requests independently. By running multiple workers, the application can process multiple requests in parallel, utilizing multiple CPU cores.
How the cluster Module Works
The cluster module is a built-in Node.js module that provides the functionality needed to implement the master-worker architecture:
Forking Workers: The master process uses the cluster.fork() method to spawn new worker processes.
Load Distribution: The master process distributes incoming client requests among the available workers, typically using a round-robin algorithm.
Inter-process Communication (IPC): Workers communicate with the master process via IPC, allowing them to send messages and handle shared server duties.
The Operating System’s Role
The operating system plays a crucial role in managing the processes created by the cluster module:
Process Scheduling: The OS schedules all processes, including the master and workers, across the available CPU cores, optimizing their execution.
Resource Allocation: It allocates resources such as memory and CPU time to each process, ensuring that they can run effectively.
Fault Tolerance: The OS can detect failed processes and allow the master process to restart workers as needed, contributing to the system’s reliability.

This diagram of the master-worker architecture illustrates how the master process forks worker processes and manages communication between them. the master process acts as the central coordinator, distributing incoming requests to multiple worker processes, each running on its CPU core. This setup enables parallel processing and efficient handling of multiple requests simultaneously.
Setting Up Your Environment
Before diving into the implementation of clustering, ensure that your development environment meets the prerequisites and that you have the necessary tools installed.
- Node.js Version: Ensure you have the latest LTS version of Node.js installed.
- System Requirements: Verify that your system has multiple CPU cores to take full advantage of clustering. Most modern computers have this, but it’s good to check.
- Apache Bench Installed: We’ll use Apache Bench to load test the server. If you’re using a MacOS, it’s already pre-installed. For other OS’es, check this Github Gist for instructions.
- Knowledge Requirements: A basic understanding of Node.js and server-side development is assumed.
Implementing Clustering in Node.js
Start by creating a new directory for your project. You can do this from your terminal or command prompt by navigating to your desired location and using the mkdir command followed by the name of your new directory. Once the directory is created, move into it with the cd command. Next, you’ll want to initialize a new Node.js project within this directory. Run npm init -y to generate a package.json file with default values.
After setting up your project’s structure, install Express.js, using this command:
npm install express
Then, create a server1.js file in your project directory. This server will not use the cluster module and will therefore not take advantage of multiple CPU cores.
const http = require('http');
const port = 3000;
const server = http.createServer((req, res) => {
// Simulate CPU-intensive task
let count = 0;
for (let i = 0; i < 1e7; i++) {
count += i;
}
res.writeHead(200);
res.end(`Handled by single thread with count: ${count}`);
});
server.listen(port, () => {
console.log(`Server running on port ${port}`);
});
This server performs a CPU-intensive task for each request, which will block the single thread and potentially lead to slow response times under high load. To prove this, let’s load test the server with Apache Bench. Run the server with node server1.js. In another terminal window, run this command:
ab -n 1000 -c 100 http://localhost:3000/
Where -n is the number of requests and -c is the level of concurrency.
You will have something like this:
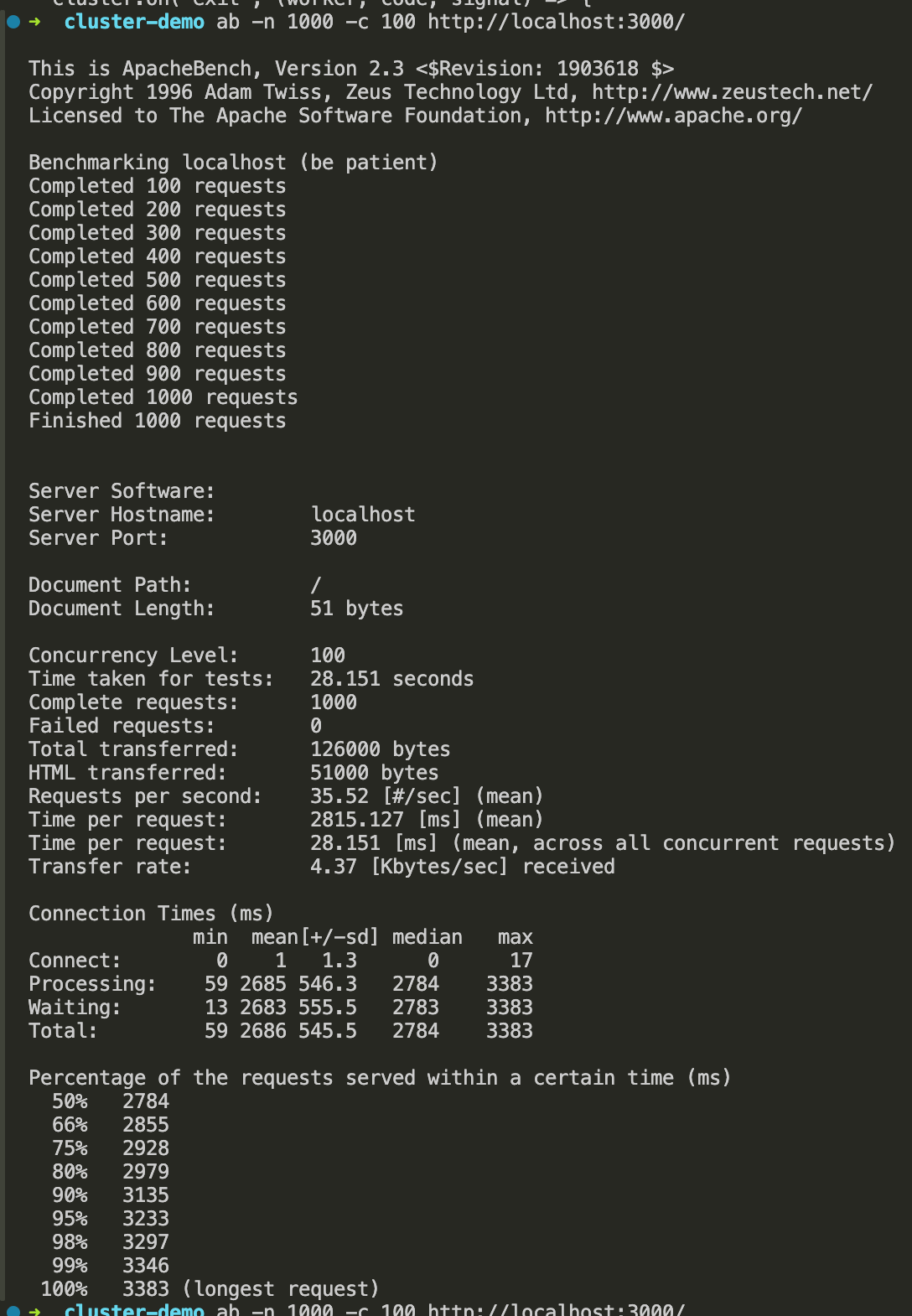
This server without the cluster module takes 28.151 seconds to handle 1000 requests, with a mean of 35.52 requests per second and a mean time per request of 28.151 milliseconds for all concurrent requests. The longest request took 3383 milliseconds to complete.
Let’s implement the same CPU-intensive task with the cluster module integrated. Create a server2.js file and add these lines of code:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
});
} else {
const server = http.createServer((req, res) => {
// Simulate CPU-intensive task
let count = 0;
for (let i = 0; i < 1e7; i++) {
count += i;
}
res.writeHead(200);
res.end(`Handled by worker ${process.pid} with count: ${count}`);
});
server.listen(3000, () => {
console.log(`Worker ${process.pid} started`);
});
}In this clustered version, multiple requests can be processed simultaneously, with each worker handling a separate request. This should result in better performance and responsiveness, especially under high load. Let’s confirm this by load testing with ab.
ab -n 1000 -c 100 http://localhost:3000/
You will get this:

Based on the Apache Bench results, this server with the cluster module enabled handled 1000 complete requests in 15.499 seconds, with a mean of 64.52 requests per second and a mean time per request of 15.499 milliseconds when considering all concurrent requests. The longest request took 1880 milliseconds to complete.
What does this result prove?
The results clearly show that the server with clustering enabled performed better, with a higher number of requests per second and a lower average time per request. This demonstrates the effectiveness of clustering in improving the performance and scalability of a Node.js application under load.
Load Balancing with Clustering
When a Node.js application is clustered, it can handle multiple connections simultaneously by distributing them across various worker processes. This distribution is known as load balancing and is key to enhancing the application’s ability to handle a high volume of traffic without any single process becoming a bottleneck.
How Node.js Distributes Incoming Connections
Node.js uses the built-in cluster module to implement load balancing across worker processes. When the master process receives incoming connections, it doesn’t handle the requests itself. Instead, it acts as a dispatcher, allocating these connections to the worker processes in a way that balances the load.
Round-Robin Scheduling Algorithm
Let’s take a look at the Round-Robin algorithm. As stated earlier the cluster module uses this algorithm for load distribution.
The default method that Node.js uses for distributing connections is the round-robin scheduling algorithm. This algorithm works by passing each new connection to the next worker in the queue, in a circular order, and then starting from the beginning once all workers have received a connection. This approach aims to distribute the workload evenly across all available workers. However, the round-robin algorithm has its limitations. For instance, it assumes that all requests will take the same amount of time to process, which is not always the case. Some requests may be more CPU-intensive than others, leading to an uneven distribution of processing time. Additionally, the round-robin method doesn’t take into account the current load of each worker, which could result in some workers being underutilized while others are overloaded.
What’s the solution to the Round-Robin Scheduling Algorithm problem?
The solution to the round-robin scheduling algorithm problem, particularly in the context of Node.js clustering, involves implementing a strategy that can more effectively distribute incoming connections to worker processes, taking into account the varying load and processing time of each request. While the round-robin algorithm distributes connections evenly, it does not consider the current load or the complexity of tasks being processed by each worker. This can lead to inefficiencies, as some workers may be idle while others are overloaded.
To address this, you could implement a more intelligent load-balancing strategy that dynamically assesses the load on each worker and distributes requests based on this information. This could involve monitoring the event loop lag, queue length, or CPU and memory usage of each worker process and adjusting the distribution of requests accordingly. Another approach is to use a load balancer that supports session persistence, also known as sticky sessions, which ensures that requests from the same client are directed to the same worker process. This can be particularly useful when dealing with stateful applications or when maintaining session data is important.
Where and When Can You Use Clustering?
Clustering is a strategy that can be employed in any situation where an application needs to handle a high volume of concurrent processes or requests efficiently. It is particularly useful in the following scenarios:
- High-Traffic Web Applications: For web servers that experience significant traffic, clustering allows for the distribution of requests across multiple workers. This ensures that no single process becomes a bottleneck, leading to improved response times and a smoother user experience.
- CPU-Intensive Operations: Applications that perform CPU-intensive tasks, such as data analysis or image processing, can benefit from clustering. By spreading these tasks across multiple CPU cores, clustering helps to reduce the processing time and prevents any single core from being overloaded.
- Microservices and Distributed Systems: In a microservices architecture or any distributed system, clustering can be used to scale services independently. This not only improves the system’s resilience and fault tolerance but also allows for more efficient resource utilization.
- Real-Time Data Processing: Clustering is perfect for applications that require real-time data processing, such as financial trading platforms or online gaming servers. It enables these applications to maintain high performance and low latency even under heavy load.
- Continuous Availability: For services that require continuous availability and cannot afford downtime, clustering provides a way to ensure that if one worker fails, others can take over, maintaining the service’s availability.
Conclusion
Clustering in Node.js is a transformative approach that enables applications to surpass the limitations of a single-threaded environment. By leveraging multiple CPU cores through a master-worker architecture, Node.js applications can handle a higher volume of concurrent requests and perform more efficiently on CPU-intensive tasks. This architecture not only boosts throughput but also enhances fault tolerance, with the master process capable of restarting any worker that fails. The round-robin scheduling algorithm, while default, has its limitations, prompting the need for more advanced load balancing strategies, especially for applications with variable request processing times or those requiring session persistence.
The practicality of clustering is evident in scenarios such as managing high-traffic web servers, executing data processing tasks, and supporting microservices architectures, all of which benefit from the improved robustness and responsiveness that clustering provides. Demonstrations comparing clustered and non-clustered setups clearly illustrate the performance advantages, making a strong case for incorporating clustering in production environments. In essence, clustering stands out as a crucial feature for enhancing the performance capabilities of Node.js applications, proving to be an invaluable tool for backend developers, DevOps engineers, and solution architects dedicated to creating high-performing, scalable systems.
Further Resources
For those interested in expanding their knowledge of clustering in Node.js, here are several resources that can provide additional information and guidance:
- Node.js Cluster Module Documentation
- Article: How to Scale Node.js applications with Clustering
- Video: Scaling your Nodejs app using the “cluster” module
- Book: Node.js Design Patterns – Second Edition