Elastic Search – Basics

There’s no secret that in modern Web applications the ability to find required content fast is one of the most important things. If your application isn’t responsive enough, clients will use something else. That’s why all the processes should be optimized as much as possible, which can be a very challenging task…
… especially with search. What makes the situation even worse is that sometimes the set of search criteria can be simply large. Let’s take a look:
1 2 3 4 5 6 7 8 9 10 11 | { account_name: 'Test', phone: '+420231231220', city: 'Prague', country: 'Czech Republic', email: 'author@gmail.com', address: 'Sokolovska, 2', secondary_address: 'Radlicka, 107', firstname: 'Jindřich', lastname: 'Chalupecký' } |
Now imagine that you need to search through such entries with pattern match (for PostgreSQL it can be done via LIKE command) while you might have thousands of such entities. The query will be very complex and heavy in that case, and you might need to join some data after all:
1 2 3 4 5 6 7 8 | SELECT * FROM customers WHERE account_name LIKE 'query%' OR city LIKE 'query%' OR country LIKE 'query%' OR email LIKE 'query%' OR firstname LIKE 'query%' OR lastname LIKE 'query%' |
Resolving such tasks is not a new kind of problem. Years ago the search indexing process was invented. The main idea is to store only searchable parts of the document and optimize the process of going through such parts. If we want to search through large entries and we know exactly what parts we’re going to search for, we can just add them into the index to do substring search faster using a search engine. (There’re many other optimizations in a search engine. You can read about the specifics here.)
One of the most popular search engines is Elastic Search, which we’re going to use with PostrgreSQL and Node.js to build a searchable grid with the entry schema above. But let’s discuss the communication between the components first:
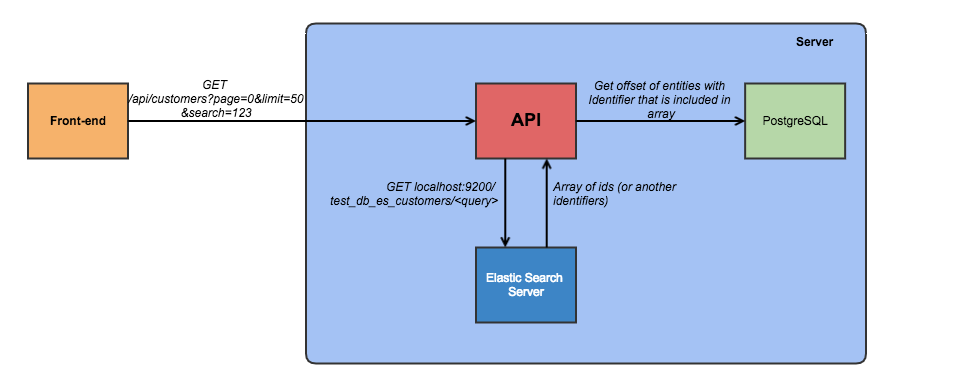
The process goes in the following way:
- Client requests data from the server API;
- Instead of taking data immediately from the DB, server requests ids from ES index;
- Elastic Search Engine goes through the indexed entries (and indexed parameters) inside and selects only ones that meet the search criteria;
- PostgreSQL selects entries based on the ES result identifiers array;
In our case (you can test the code base yourself, the link is below) we’re going to search through 10000 entities. For the search index we’re going to take just a few parameters with one customized (but again you can change the algorithm of entities’ generation and test performance, the request will be really fast). In that case the configuration for our ORM model can look like this (in order to make code simpler we used Sequelize ORM, nothing outstanding, just common ORM) for search usage later:
1 2 3 4 5 6 | model.getSearchOptions = () => { return { type: 'customers', keys: ['account_name', 'city', 'country' ] } } |
Here we specify what name of search index collection is going to be used and what properties of actual data should be indexed. There’s one rule for you guys: know your data and queries! Never index everything that’s saved in DB if it can be avoided. Analyze for what kind of data the user expects to have a search. For example, if we had a phone number book, I would index phone, last name and first name as most common searchable fields. But how are those props connected with actual search index? Good question. And here we need to discuss another pitfall of ES usage – data duplication:
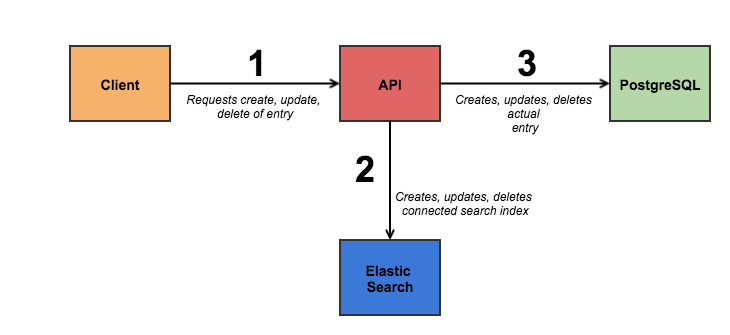
So each change in the database should be reflected in the search index. We save the same data twice. Sounds a bit complex, but there’s the easy way: usage of middleware!
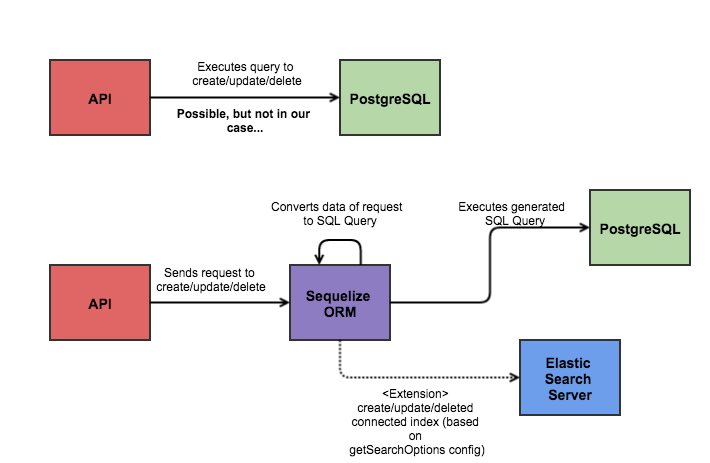
Actually we already have one – Sequelize ORM. Nowadays it’s common practice to use ORM as a provider of connection to DB to have all the models, relations, etc. easily readable and well-structured. We can use ORM functionality for the same purpose: it will provide the interface for indexing inside ES server. So we’re going to kill 2 birds with one stone – change index and db with one abstraction with no duplicate code every time when we need to do such operations (the idea is not a new one, you can easily find such extensions for another ORMs, like mongoosastic for MongoDB ORM). But if there’s no ready-to-use solution, you might need to decorate the existing create/update/delete methods. Let’s take a look at a possible way:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | module.exports = (model, client, database) => { const originalCreateMethod = model[methods.create]; const options = model.getSearchOptions(); model.originalCreate = originalCreateMethod; model[methods.create] = async entry => { return new Promise(resolve => { model.originalCreate(entry).then(created => { let body = {}; options.keys.map(key => { body[key] = created[key]; }); client.index({ index: `${database}_${options.type}`, id: created.id, type: 'doc', body }).then(() => resolve(created)); }); }); }; }; |
As you can see, we provide decorator in the form of a module. It saves the original create method and extends with Elastic Search indexing functionality. So whenever the user calls original ORM create, it will automatically create the search index of the created entity. You can easily do the same extension for update and delete as well.
And now when we have our data indexed, it’s a time to do a simple search. We’re going to do the promised substring search:
1 2 3 4 5 6 7 | esClient.search({ size: 1000, index: `${config.dbName}_customers`, q: `*${queryVal}*` })).hits .hits .map(entry => entry._id); |
So we do a search for query pushed by the user and filter out identifiers in the form of array so it can be used for querying of entries from the actual DB.
Waiting for your comments and questions below! All the code can be found here.
We are looking forward to meeting you on our website soshace.com
About the author



Top developers
-

 Milan M. Full Stack Javascript DeveloperAngularNode.jsJSShow lessAll skills
Milan M. Full Stack Javascript DeveloperAngularNode.jsJSShow lessAll skills Bryan C. Full-stack JavaScript developerAngularCSSJSNode.jsShow lessAll skills
Bryan C. Full-stack JavaScript developerAngularCSSJSNode.jsShow lessAll skills Miodrag M. Senior React developer
Miodrag M. Senior React developerRelated articles

 15.03.2024
15.03.2024JAMstack Architecture with Next.js
The Jamstack architecture, a term coined by Mathias Biilmann, the co-founder of Netlify, encompasses a set of structural practices that rely on ...
 19.01.2024
19.01.2024Training DALL·E on Custom Datasets: A Practical Guide
The adaptability of DALL·E across diverse datasets is it’s key strength and that’s where DALL·E’s neural network design stands out for its ...

 12.06.2023
12.06.2023The Ultimate Guide to Pip
Developers may quickly and easily install Python packages from the Python Package Index (PyPI) and other package indexes by using Pip. Pip ...
Categories



No comments yet